Rory Donovan
January 20, 2023
0 comments

Every year, a new AI scandal emerges to shock the public. In 2016, the country learned that some law-enforcement algorithms routinely recommended incarcerating members of minority groups. Google discovered in 2017 that its Min smart speakers were secretly spying on their owners by turning them on at random, recording audio from their homes, and transmitting the audio files to Google. In 2018, the Facebook-Cambridge Analytica scandal rocked the United States and Europe, with millions of Facebook users’ data illegally harvested for apparent use in political campaigns. In 2019, healthcare organizations attempting to identify and assist at-risk patients used algorithms that routinely excluded African American participants due to assumptions built into their systems. A medical chatbot advised a patient to commit suicide in a simulated session in 2020. In 2021, a Facebook algorithm recommended videos about “other primates” after showing one containing a group of black men. Failures like this demonstrate how important AI ethics has become. AI promises many benefits, but they come with significant societal risks. Educating developers, corporations, lawmakers, and the public about Ethical AI and AI ethics are critical to developing safe and effective artificial intelligence systems.
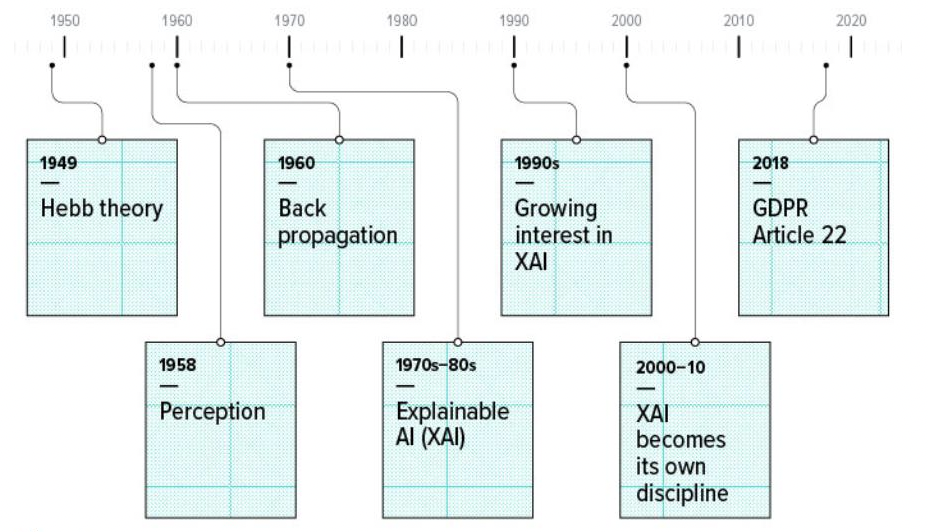
In 1949, Donald O. Hebb proposed Hebb’s Theory, which states that neurons that “fire together wire together.” Later, in 1958, Frank Rosenblatt invented the perceptron, a multi-layered binary classifier based on an artificial neural network (ANN). The ANN performed combinations of logical and mathematical operations as part of a process known as supervised learning. Finally, in 1960, Henry J. Kelley laid the foundations for backpropagation, a method of updating weights along an error gradient, allowing any neural network with differential layers to be recursively updated [14]. Since it was established that multi-layered perceptrons could solve non-linear problems and perform backpropagation, there has been rapid development in artificial intelligence (AI). Yet, ethical AI is just now starting to catch on.
Artificial Intelligence (AI) has suffered setbacks due to researchers’ inability to interpret obscure black-box algorithms, but this has helped spur current interest in explainable artificial intelligence (XAI). Some research into XAI occurred in the 1970s and 1980s, and many argue that despite the waning interest in AI proper, no significant decline occurred in XAI’s popularity. Instead, interest in it gradually increased during the 1990s, reaching a substantial concentration in 2000 that led to it becoming its own discursive body by 2010 [15]. The industry began giving the most extreme attention to transparency in the 2010s, particularly in 2018 [#] with Article 22 of the GDPR, which mandated that developers provide explanations for AI’s decisions in sensitive applications that impact physical or emotional well-being. During this final decade, it began infiltrating all the major industries which could be attributed to a growing increase in popularity.
Despite the transformative power of AI and its wide adoption in the industry, regulatory efforts for ethical AI have consistently failed to keep up with its development. This has been particularly true with exponential growth within the past decade. Public awareness of AI has historically been limited to intelligent robots portrayed in stories and films such as “I Robot,” and theories of laws to govern AI have been limited to Isaac Asimov’s Three Rules of Robotics, constructed for his sci-fi universe in the 1940s. Since the advent of modern artificial intelligence in the form of machine learning algorithms, many incidents have occurred in which AI has breached ethical norms and demonstrated the need for regulation. Everyone is aware of a problem with an almost clichéd level of bias in the industry. There are other scandals involving racist robots, such as Microsoft’s Tay, a Twitter chatbot that swiftly picked up on racism from the users it communicated with.
Ethical AI robot trained on Reddit data that stated that genocide was okay “as long as everyone said it was”. Facebook’s data breaches and privacy regulations show how organizations with well-crafted algorithms and access to data can influence massive groups of people online for the gain of a political candidate. With almost a free hand to access hundreds of thousands of profiles connected to a much smaller group of individuals who consented to have their information accessed, Cambridge-Analytica demonstrated the kind of social and political havoc that AI in the hands of unethical actors can wreak. This freedom Facebook and Cambridge-Analytica had to act highlights how slow regulatory control has come to AI. Only in the last few years have privacy laws and guidelines started to be introduced to ensure the ethical collection of data, its transparent use, and the accountability of algorithms’ creators. Such regulations include the European Union’s General Data Protection Regulation (GDPR), the United States Children’s Online Privacy Protection Rule (COPPA), and the California State Legislature’s Automated Decision Systems Accountability Act.
Managers, practitioners, and legislators need to be educated to combat the potential pitfalls of using artificial intelligence (AI). Furthermore, methods of increasing accountability need to be implemented.
Data has shown that only 18% of people preparing for a career in data science learn about the ethics of artificial intelligence. This low proportion makes it imperative that universities begin pursuing strategies for educating students in the field of ethics. Also, leaders often do not understand the complexity of creating ethical AI and assume that the developers can figure it out. However, this is not the case. Both parties need to be educated on the dangers of AI. Lastly, lawmakers need to be informed of the pitfalls of AI to tell law-making.
This is when inner mechanisms are available for scrutiny. Because the industry generally favors obscure models, those who commission algorithms have likely not naturally pursued algorithmic transparency. An algorithm’s commissioners often prefer to keep its components secret and hidden from the knowledge of those they consider to be competitors. In highly competitive industries, it is customary for companies to have trade secrets that protect both proprietary material and their intellectual property. These “trade secrets” provide a competitive advantage because they are not known to others and for which reasonable safeguards are maintained to protect their secrecy.
It has also been in the industry’s best interest to hide algorithms’ operations from the public on whose data they feed. The hyper-complexity of algorithms and the difficulty humans have understanding them enables them to violate their users’ privacy by training models on data the algorithms have extracted without those users’ knowledge. In most cases, software documentation would enhance the transparency of the algorithm. However, companies often avoid the effort because it requires significant time and financial investment. The incentive to do this lessens since they can use the promise of advanced and inscrutable models to attract funding for their projects.
An important reason why accountability in AI often fails is that it lacks a reinforcement mechanism. It occurs for the following reasons: the wash currently happening in the AI ethics world and the general diffusion of responsibility for AI functions or malfunctions.
People or companies creating software that runs on AI or machine learning have the privilege of creating their own rules regarding ethical responsibility. With no single set of guidelines that developers can follow, it is difficult to identify when an AI model has met, exceeded, or fallen short of ethical standards. Furthermore, responsibility becomes diffuse in the following two-part situation: (1) AI developers do their work but trust that scrutiny from their boss will monitor any regulatory or ethical issues arising from the software. (2) Simultaneously, the bosses trust developers to make high-quality decisions. Ethical responsibilities are likely to be neglected in such situations. Moral obligations are likely to be ignored because no single person (or office) bears direct responsibility for them.
Open-source research still needs to be conducted to make algorithms more responsible. Data, models, and findings must be publicly available and presented to the social sector.
The acronym REGRET provides a guide to exploring the ethics of artificial intelligence (AI) by categorizing the problem in terms that require that models’ engineers be responsible for ensuring that their algorithms perform equitably and are governable, reliable, and traceable so that they can be trusted.
Responsible
Human beings developing AI need to exercise judgement in using A.I. (security, privacy, green AI).
Equitable
Should take deliberate steps to avoid systemic disadvantage to individuals in A.I. recognition.
Governable
It needs “the ability to detect and avoid unintended harm or disruption.” The acronym REGRET serves as a guide to investigating the ethics of artificial intelligence (AI) by categorizing the problem in terms that require model engineers to be accountable for ensuring that their algorithms perform equitably and are governable, reliable, and traceable so that they can be trusted.
Reliable
It should have a “well-defined domain of use”, track performance and improve results, and prove consistency and reproducibility.
Transparent
It should open the black box up so that it is able to explain how the answer was reached at each step of the way to justify, debug, improve, learn, and have accountability.
Interested in learning more about how to develop ethical AI? Our firm can help you put best practices in place to better serve your customers? Contact us! Quickly develop ethical AI that is explainable, equitable, and reliable with help from our complete AI IaaS. Sign up for FREE diagnostics.
Comments